ChIP-seq Genomic Range Annotation#
import genomic_features as gf
import bioframe
import seaborn
import matplotlib.pyplot as plt
import numpy as np
Download example data#
The data used in this tutorial is ChIP-seq IDR ranked peaks with target CTCF, downloaded from ENCODE (accession: ENCFF417KHZ). The data is from CRISPR modified homo sapiens cell line HCT116 and more information about the dataset can be found on the ENCODE website here. Column names are assigned by bioframe using the function read_table() based on the column contents.
ctcf_peak = bioframe.read_table(
"https://www.encodeproject.org/files/ENCFF417KHZ/@@download/ENCFF417KHZ.bed.gz",
schema="narrowPeak",
)
ctcf_peak
| chrom | start | end | name | score | strand | fc | -log10p | -log10q | relSummit | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chr10 | 99392395 | 99392827 | . | 1000 | . | 306.78095 | -1.0 | 4.96085 | 230 |
| 1 | chr3 | 194929204 | 194929707 | . | 1000 | . | 284.09197 | -1.0 | 4.96085 | 234 |
| 2 | chr8 | 97559907 | 97560401 | . | 1000 | . | 284.16880 | -1.0 | 4.96085 | 242 |
| 3 | chr8 | 66609310 | 66609747 | . | 1000 | . | 265.66492 | -1.0 | 4.96085 | 238 |
| 4 | chr15 | 66903598 | 66904095 | . | 1000 | . | 263.27660 | -1.0 | 4.96085 | 252 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 129238 | chr17 | 55794221 | 55794717 | . | 78 | . | 5.91739 | -1.0 | 0.35122 | 248 |
| 129239 | chr5 | 39135451 | 39135947 | . | 78 | . | 6.62387 | -1.0 | 0.51343 | 248 |
| 129240 | chr20 | 16241885 | 16242381 | . | 78 | . | 8.24784 | -1.0 | 0.96486 | 248 |
| 129241 | chr2 | 39231186 | 39231682 | . | 78 | . | 6.21278 | -1.0 | 0.42335 | 248 |
| 129242 | chr16 | 84553939 | 84554435 | . | 78 | . | 8.06121 | -1.0 | 0.91185 | 248 |
129243 rows × 10 columns
Download Ensembl annotations using genomic_features#
Using the genomic ranges provided in the bed file’s chrom, start, and end columns we can ascribe an ensembl gene id from EnsemblDB to each peak. Read in the correct ensembl annotation version to match to the data.
It’s possible to add more columns to the returned dataframe if exon, protein, or sequence information that is not included by default is needed. The function list_columns() shows all possible columns.
ensdb = gf.ensembl.annotation(species="Hsapiens", version="108")
ensdb.list_columns()
['seq_name',
'seq_length',
'is_circular',
'gene_id',
'entrezid',
'exon_id',
'exon_seq_start',
'exon_seq_end',
'gene_id',
'gene_name',
'gene_biotype',
'gene_seq_start',
'gene_seq_end',
'seq_name',
'seq_strand',
'seq_coord_system',
'description',
'gene_id_version',
'canonical_transcript',
'name',
'value',
'tx_id',
'protein_id',
'protein_sequence',
'protein_id',
'protein_domain_id',
'protein_domain_source',
'interpro_accession',
'prot_dom_start',
'prot_dom_end',
'tx_id',
'tx_biotype',
'tx_seq_start',
'tx_seq_end',
'tx_cds_seq_start',
'tx_cds_seq_end',
'gene_id',
'tx_support_level',
'tx_id_version',
'gc_content',
'tx_external_name',
'tx_is_canonical',
'tx_id',
'exon_id',
'exon_idx',
'protein_id',
'uniprot_id',
'uniprot_db',
'uniprot_mapping_type']
genes = ensdb.genes(
filter=gf.filters.GeneBioTypeFilter("protein_coding"),
)
genes
| gene_id | gene_name | gene_biotype | gene_seq_start | gene_seq_end | seq_name | seq_strand | seq_coord_system | description | gene_id_version | canonical_transcript | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ENSG00000000003 | TSPAN6 | protein_coding | 100627108 | 100639991 | X | -1 | chromosome | tetraspanin 6 [Source:HGNC Symbol;Acc:HGNC:11858] | ENSG00000000003.15 | ENST00000373020 |
| 1 | ENSG00000000005 | TNMD | protein_coding | 100584936 | 100599885 | X | 1 | chromosome | tenomodulin [Source:HGNC Symbol;Acc:HGNC:17757] | ENSG00000000005.6 | ENST00000373031 |
| 2 | ENSG00000000419 | DPM1 | protein_coding | 50934867 | 50959140 | 20 | -1 | chromosome | dolichyl-phosphate mannosyltransferase subunit... | ENSG00000000419.14 | ENST00000371588 |
| 3 | ENSG00000000457 | SCYL3 | protein_coding | 169849631 | 169894267 | 1 | -1 | chromosome | SCY1 like pseudokinase 3 [Source:HGNC Symbol;A... | ENSG00000000457.14 | ENST00000367771 |
| 4 | ENSG00000000460 | C1orf112 | protein_coding | 169662007 | 169854080 | 1 | 1 | chromosome | chromosome 1 open reading frame 112 [Source:HG... | ENSG00000000460.17 | ENST00000359326 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 22890 | ENSG00000290318 | protein_coding | 49357176 | 49412051 | 3 | -1 | chromosome | novel protein | ENSG00000290318.1 | ENST00000704381 | |
| 22891 | ENSG00000290320 | H2BN1 | protein_coding | 32895433 | 32906586 | 17 | 1 | chromosome | H2B.N variant histone 1 [Source:HGNC Symbol;Ac... | ENSG00000290320.1 | ENST00000704639 |
| 22892 | ENSG00000291237 | SOD2 | protein_coding | 159669069 | 159762529 | 6 | -1 | chromosome | superoxide dismutase 2 [Source:HGNC Symbol;Acc... | ENSG00000291237.1 | ENST00000538183 |
| 22893 | ENSG00000291239 | protein_coding | 36850858 | 36998682 | 19 | 1 | chromosome | novel protein | ENSG00000291239.1 | ENST00000706165 | |
| 22894 | ENSG00000291240 | protein_coding | 21008247 | 21032572 | 22 | -1 | chromosome | novel protein | ENSG00000291240.1 | ENST00000706202 |
22895 rows × 11 columns
Mapping chromosome annotation styles#
In order to annotate the ranges in the dataframe with gene symbols, ensembl ids, strand direction, etc. the two dataframes need to be merged. To make this seamless we use the bioframe assembly_info to map the numeric Ensembl chromosome annotation with the “chr” notation of the CHIP-Seq dataset and remove any peaks with unmapped chromosome values. This step is optional but makes joining the two dataframes much simpler in the next step.
from bioframe import assembly_info
hg38 = assembly_info("hg38")
genes["seq_name"] = genes["seq_name"].map(hg38.alias_dict)
genes = genes.dropna(subset="seq_name")
genes
| gene_id | gene_name | gene_biotype | gene_seq_start | gene_seq_end | seq_name | seq_strand | seq_coord_system | description | gene_id_version | canonical_transcript | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ENSG00000000003 | TSPAN6 | protein_coding | 100627108 | 100639991 | chrX | -1 | chromosome | tetraspanin 6 [Source:HGNC Symbol;Acc:HGNC:11858] | ENSG00000000003.15 | ENST00000373020 |
| 1 | ENSG00000000005 | TNMD | protein_coding | 100584936 | 100599885 | chrX | 1 | chromosome | tenomodulin [Source:HGNC Symbol;Acc:HGNC:17757] | ENSG00000000005.6 | ENST00000373031 |
| 2 | ENSG00000000419 | DPM1 | protein_coding | 50934867 | 50959140 | chr20 | -1 | chromosome | dolichyl-phosphate mannosyltransferase subunit... | ENSG00000000419.14 | ENST00000371588 |
| 3 | ENSG00000000457 | SCYL3 | protein_coding | 169849631 | 169894267 | chr1 | -1 | chromosome | SCY1 like pseudokinase 3 [Source:HGNC Symbol;A... | ENSG00000000457.14 | ENST00000367771 |
| 4 | ENSG00000000460 | C1orf112 | protein_coding | 169662007 | 169854080 | chr1 | 1 | chromosome | chromosome 1 open reading frame 112 [Source:HG... | ENSG00000000460.17 | ENST00000359326 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 22890 | ENSG00000290318 | protein_coding | 49357176 | 49412051 | chr3 | -1 | chromosome | novel protein | ENSG00000290318.1 | ENST00000704381 | |
| 22891 | ENSG00000290320 | H2BN1 | protein_coding | 32895433 | 32906586 | chr17 | 1 | chromosome | H2B.N variant histone 1 [Source:HGNC Symbol;Ac... | ENSG00000290320.1 | ENST00000704639 |
| 22892 | ENSG00000291237 | SOD2 | protein_coding | 159669069 | 159762529 | chr6 | -1 | chromosome | superoxide dismutase 2 [Source:HGNC Symbol;Acc... | ENSG00000291237.1 | ENST00000538183 |
| 22893 | ENSG00000291239 | protein_coding | 36850858 | 36998682 | chr19 | 1 | chromosome | novel protein | ENSG00000291239.1 | ENST00000706165 | |
| 22894 | ENSG00000291240 | protein_coding | 21008247 | 21032572 | chr22 | -1 | chromosome | novel protein | ENSG00000291240.1 | ENST00000706202 |
20012 rows × 11 columns
Merging genomic ranges to annotate Ensembl ids and gene names#
When joining the two dataframes we can use the overlap() function to join the dataframes based on the gene region the peak overlaps with the most. The cols1 option passes synonymous column names from the ensembl dataframe to the corresponding ctcf peak columns for matching. Now each remaining peak has an ensembl id and gene name.
gene_ov = bioframe.overlap(
ctcf_peak, genes, cols2=["seq_name", "gene_seq_start", "gene_seq_end"], how="inner"
)
gene_ov
| chrom | start | end | name | score | strand | fc | -log10p | -log10q | relSummit | ... | gene_name_ | gene_biotype_ | gene_seq_start_ | gene_seq_end_ | seq_name_ | seq_strand_ | seq_coord_system_ | description_ | gene_id_version_ | canonical_transcript_ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chr22 | 17563181 | 17563677 | . | 748 | . | 23.66046 | -1.0 | 4.96085 | 248 | ... | SLC25A18 | protein_coding | 17563450 | 17590995 | chr22 | 1 | chromosome | solute carrier family 25 member 18 [Source:HGN... | ENSG00000182902.14 | ENST00000327451 |
| 1 | chr22 | 19179353 | 19179849 | . | 800 | . | 37.47772 | -1.0 | 4.96085 | 248 | ... | CLTCL1 | protein_coding | 19179473 | 19291719 | chr22 | -1 | chromosome | clathrin heavy chain like 1 [Source:HGNC Symbo... | ENSG00000070371.16 | ENST00000427926 |
| 2 | chr22 | 19756445 | 19756941 | . | 885 | . | 35.76666 | -1.0 | 4.96085 | 248 | ... | TBX1 | protein_coding | 19756703 | 19783593 | chr22 | 1 | chromosome | T-box transcription factor 1 [Source:HGNC Symb... | ENSG00000184058.16 | ENST00000649276 |
| 3 | chr22 | 20016770 | 20017266 | . | 176 | . | 11.34425 | -1.0 | 2.13939 | 248 | ... | TANGO2 | protein_coding | 20017014 | 20067164 | chr22 | 1 | chromosome | transport and golgi organization 2 homolog [So... | ENSG00000183597.16 | ENST00000327374 |
| 4 | chr22 | 20916962 | 20917458 | . | 484 | . | 22.82968 | -1.0 | 4.96085 | 248 | ... | CRKL | protein_coding | 20917407 | 20953747 | chr22 | 1 | chromosome | CRK like proto-oncogene, adaptor protein [Sour... | ENSG00000099942.13 | ENST00000354336 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 73773 | chr8 | 144895624 | 144896120 | . | 78 | . | 8.95825 | -1.0 | 1.20680 | 248 | ... | ZNF250 | protein_coding | 144876497 | 144902168 | chr8 | -1 | chromosome | zinc finger protein 250 [Source:HGNC Symbol;Ac... | ENSG00000196150.14 | ENST00000417550 |
| 73774 | chr8 | 144900092 | 144900588 | . | 1000 | . | 63.47950 | -1.0 | 4.96085 | 248 | ... | ZNF250 | protein_coding | 144876497 | 144902168 | chr8 | -1 | chromosome | zinc finger protein 250 [Source:HGNC Symbol;Ac... | ENSG00000196150.14 | ENST00000417550 |
| 73775 | chr8 | 144901897 | 144902393 | . | 454 | . | 37.27992 | -1.0 | 4.96085 | 248 | ... | ZNF250 | protein_coding | 144876497 | 144902168 | chr8 | -1 | chromosome | zinc finger protein 250 [Source:HGNC Symbol;Ac... | ENSG00000196150.14 | ENST00000417550 |
| 73776 | chr8 | 144934494 | 144934990 | . | 385 | . | 12.88503 | -1.0 | 2.82659 | 248 | ... | ZNF16 | protein_coding | 144930358 | 144950888 | chr8 | -1 | chromosome | zinc finger protein 16 [Source:HGNC Symbol;Acc... | ENSG00000170631.15 | ENST00000394909 |
| 73777 | chr8 | 145065907 | 145066403 | . | 78 | . | 10.13864 | -1.0 | 1.63946 | 248 | ... | C8orf33 | protein_coding | 145052465 | 145066685 | chr8 | 1 | chromosome | chromosome 8 open reading frame 33 [Source:HGN... | ENSG00000182307.14 | ENST00000331434 |
73778 rows × 21 columns
Annotating exons and introns#
Ensembl DB also has an exon table that we can use to select exon/intron peaks if they were not already loaded via the gene table. To keep consistent chromosome style, we again map seq_name using bioframe and drop unmapped chromosome names.
exons = ensdb.exons(filter=gf.filters.GeneIDFilter(gene_ov["gene_id_"]))
exons["seq_name"] = exons["seq_name"].map(hg38.alias_dict)
exons = exons.dropna(subset="seq_name")
exons
| exon_id | exon_seq_start | exon_seq_end | seq_name | gene_id | |
|---|---|---|---|---|---|
| 0 | ENSE00001855382 | 100636608 | 100636806 | chrX | ENSG00000000003 |
| 1 | ENSE00003662440 | 100635558 | 100635746 | chrX | ENSG00000000003 |
| 2 | ENSE00003654571 | 100635178 | 100635252 | chrX | ENSG00000000003 |
| 3 | ENSE00003658810 | 100633931 | 100634029 | chrX | ENSG00000000003 |
| 4 | ENSE00003554016 | 100633405 | 100633539 | chrX | ENSG00000000003 |
| ... | ... | ... | ... | ... | ... |
| 513101 | ENSE00003995056 | 21029711 | 21030351 | chr22 | ENSG00000291240 |
| 513102 | ENSE00003995060 | 21029336 | 21029444 | chr22 | ENSG00000291240 |
| 513103 | ENSE00003995062 | 21013042 | 21013184 | chr22 | ENSG00000291240 |
| 513104 | ENSE00003995061 | 21011384 | 21011590 | chr22 | ENSG00000291240 |
| 513105 | ENSE00003995059 | 21008247 | 21009449 | chr22 | ENSG00000291240 |
513106 rows × 5 columns
We can overlap our peaks again to annotate the peaks that are overlapping exon regions and subsequently label non-overlapping peaks as introns.
exon_ov = bioframe.overlap(
gene_ov,
exons,
cols2=["seq_name", "exon_seq_start", "exon_seq_end"],
how="left",
)
exon_ov
| chrom | start | end | name | score | strand | fc | -log10p | -log10q | relSummit | ... | seq_strand_ | seq_coord_system_ | description_ | gene_id_version_ | canonical_transcript_ | exon_id_ | exon_seq_start_ | exon_seq_end_ | seq_name_ | gene_id_ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chr22 | 17563181 | 17563677 | . | 748 | . | 23.66046 | -1.0 | 4.96085 | 248 | ... | 1 | chromosome | solute carrier family 25 member 18 [Source:HGN... | ENSG00000182902.14 | ENST00000327451 | ENSE00001540287 | 17563450 | 17563713 | chr22 | ENSG00000182902 |
| 1 | chr22 | 17563181 | 17563677 | . | 748 | . | 23.66046 | -1.0 | 4.96085 | 248 | ... | 1 | chromosome | solute carrier family 25 member 18 [Source:HGN... | ENSG00000182902.14 | ENST00000327451 | ENSE00001430286 | 17563464 | 17563713 | chr22 | ENSG00000182902 |
| 2 | chr22 | 17563181 | 17563677 | . | 748 | . | 23.66046 | -1.0 | 4.96085 | 248 | ... | 1 | chromosome | solute carrier family 25 member 18 [Source:HGN... | ENSG00000182902.14 | ENST00000327451 | ENSE00001955974 | 17563498 | 17563713 | chr22 | ENSG00000182902 |
| 3 | chr22 | 17563181 | 17563677 | . | 748 | . | 23.66046 | -1.0 | 4.96085 | 248 | ... | 1 | chromosome | solute carrier family 25 member 18 [Source:HGN... | ENSG00000182902.14 | ENST00000327451 | ENSE00001866696 | 17563589 | 17563713 | chr22 | ENSG00000182902 |
| 4 | chr22 | 19179353 | 19179849 | . | 800 | . | 37.47772 | -1.0 | 4.96085 | 248 | ... | -1 | chromosome | clathrin heavy chain like 1 [Source:HGNC Symbo... | ENSG00000070371.16 | ENST00000427926 | ENSE00003739095 | 19179473 | 19179969 | chr22 | ENSG00000070371 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 111113 | chr8 | 144934494 | 144934990 | . | 385 | . | 12.88503 | -1.0 | 2.82659 | 248 | ... | -1 | chromosome | zinc finger protein 16 [Source:HGNC Symbol;Acc... | ENSG00000170631.15 | ENST00000394909 | None | <NA> | <NA> | None | None |
| 111114 | chr8 | 145065907 | 145066403 | . | 78 | . | 10.13864 | -1.0 | 1.63946 | 248 | ... | 1 | chromosome | chromosome 8 open reading frame 33 [Source:HGN... | ENSG00000182307.14 | ENST00000331434 | ENSE00003839769 | 145065708 | 145066516 | chr8 | ENSG00000182307 |
| 111115 | chr8 | 145065907 | 145066403 | . | 78 | . | 10.13864 | -1.0 | 1.63946 | 248 | ... | 1 | chromosome | chromosome 8 open reading frame 33 [Source:HGN... | ENSG00000182307.14 | ENST00000331434 | ENSE00003840227 | 145065715 | 145066624 | chr8 | ENSG00000182307 |
| 111116 | chr8 | 145065907 | 145066403 | . | 78 | . | 10.13864 | -1.0 | 1.63946 | 248 | ... | 1 | chromosome | chromosome 8 open reading frame 33 [Source:HGN... | ENSG00000182307.14 | ENST00000331434 | ENSE00003838341 | 145065708 | 145066679 | chr8 | ENSG00000182307 |
| 111117 | chr8 | 145065907 | 145066403 | . | 78 | . | 10.13864 | -1.0 | 1.63946 | 248 | ... | 1 | chromosome | chromosome 8 open reading frame 33 [Source:HGN... | ENSG00000182307.14 | ENST00000331434 | ENSE00003835531 | 145065708 | 145066685 | chr8 | ENSG00000182307 |
111118 rows × 26 columns
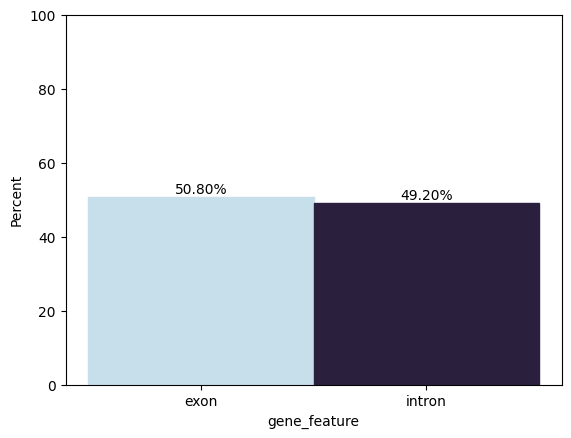
Now we can label the peaks that are mapped to exons as exons and those that are not mapped as introns. A coarser definition is encouraged for introns depending on where the sequence lands in the gene position.
exon_ov["gene_feature"] = np.where(exon_ov["exon_id_"].isnull(), "intron", "exon")
exon_ov
| chrom | start | end | name | score | strand | fc | -log10p | -log10q | relSummit | ... | seq_coord_system_ | description_ | gene_id_version_ | canonical_transcript_ | exon_id_ | exon_seq_start_ | exon_seq_end_ | seq_name_ | gene_id_ | gene_feature | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chr22 | 17563181 | 17563677 | . | 748 | . | 23.66046 | -1.0 | 4.96085 | 248 | ... | chromosome | solute carrier family 25 member 18 [Source:HGN... | ENSG00000182902.14 | ENST00000327451 | ENSE00001540287 | 17563450 | 17563713 | chr22 | ENSG00000182902 | exon |
| 1 | chr22 | 17563181 | 17563677 | . | 748 | . | 23.66046 | -1.0 | 4.96085 | 248 | ... | chromosome | solute carrier family 25 member 18 [Source:HGN... | ENSG00000182902.14 | ENST00000327451 | ENSE00001430286 | 17563464 | 17563713 | chr22 | ENSG00000182902 | exon |
| 2 | chr22 | 17563181 | 17563677 | . | 748 | . | 23.66046 | -1.0 | 4.96085 | 248 | ... | chromosome | solute carrier family 25 member 18 [Source:HGN... | ENSG00000182902.14 | ENST00000327451 | ENSE00001955974 | 17563498 | 17563713 | chr22 | ENSG00000182902 | exon |
| 3 | chr22 | 17563181 | 17563677 | . | 748 | . | 23.66046 | -1.0 | 4.96085 | 248 | ... | chromosome | solute carrier family 25 member 18 [Source:HGN... | ENSG00000182902.14 | ENST00000327451 | ENSE00001866696 | 17563589 | 17563713 | chr22 | ENSG00000182902 | exon |
| 4 | chr22 | 19179353 | 19179849 | . | 800 | . | 37.47772 | -1.0 | 4.96085 | 248 | ... | chromosome | clathrin heavy chain like 1 [Source:HGNC Symbo... | ENSG00000070371.16 | ENST00000427926 | ENSE00003739095 | 19179473 | 19179969 | chr22 | ENSG00000070371 | exon |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 111113 | chr8 | 144934494 | 144934990 | . | 385 | . | 12.88503 | -1.0 | 2.82659 | 248 | ... | chromosome | zinc finger protein 16 [Source:HGNC Symbol;Acc... | ENSG00000170631.15 | ENST00000394909 | None | <NA> | <NA> | None | None | intron |
| 111114 | chr8 | 145065907 | 145066403 | . | 78 | . | 10.13864 | -1.0 | 1.63946 | 248 | ... | chromosome | chromosome 8 open reading frame 33 [Source:HGN... | ENSG00000182307.14 | ENST00000331434 | ENSE00003839769 | 145065708 | 145066516 | chr8 | ENSG00000182307 | exon |
| 111115 | chr8 | 145065907 | 145066403 | . | 78 | . | 10.13864 | -1.0 | 1.63946 | 248 | ... | chromosome | chromosome 8 open reading frame 33 [Source:HGN... | ENSG00000182307.14 | ENST00000331434 | ENSE00003840227 | 145065715 | 145066624 | chr8 | ENSG00000182307 | exon |
| 111116 | chr8 | 145065907 | 145066403 | . | 78 | . | 10.13864 | -1.0 | 1.63946 | 248 | ... | chromosome | chromosome 8 open reading frame 33 [Source:HGN... | ENSG00000182307.14 | ENST00000331434 | ENSE00003838341 | 145065708 | 145066679 | chr8 | ENSG00000182307 | exon |
| 111117 | chr8 | 145065907 | 145066403 | . | 78 | . | 10.13864 | -1.0 | 1.63946 | 248 | ... | chromosome | chromosome 8 open reading frame 33 [Source:HGN... | ENSG00000182307.14 | ENST00000331434 | ENSE00003835531 | 145065708 | 145066685 | chr8 | ENSG00000182307 | exon |
111118 rows × 27 columns
# Create a histogram
palette = seaborn.color_palette(
"ch:s=.25,rot=-.25", len(exon_ov["gene_feature"].unique())
)
ax = seaborn.histplot(exon_ov["gene_feature"], stat="percent")
# Set ylim
plt.ylim(0, 100)
# Assigning different colors to each bar
for i, bar in enumerate(ax.patches):
bar.set_color(palette[i])
# Add values on top of the bars
for p in ax.patches:
ax.annotate(
f"{p.get_height():.2f}%",
(p.get_x() + p.get_width() / 2.0, p.get_height()),
ha="center",
va="center",
fontsize=10,
color="black",
xytext=(0, 5),
textcoords="offset points",
)
# Show the plot
plt.show()
Similarly, it is possible to categorize peaks into promoter, gene body, etc. groups based on distance and upstream/downstream thresholds using bioframe. Promoter region peaks are filtered here using a maximum threshold of 2000kb upstream from promoter region.
out = bioframe.closest(
genes,
ctcf_peak,
cols1=["seq_name", "gene_seq_start", "gene_seq_end"],
ignore_overlaps=True,
ignore_downstream=True,
k=1,
)
out[
out["distance"] < 2000
] # filter for peaks 2000kb upstream or closer to promoter region
out
| gene_id | gene_name | gene_biotype | gene_seq_start | gene_seq_end | seq_name | seq_strand | seq_coord_system | description | gene_id_version | ... | start_ | end_ | name_ | score_ | strand_ | fc_ | -log10p_ | -log10q_ | relSummit_ | distance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ENSG00000000457 | SCYL3 | protein_coding | 169849631 | 169894267 | chr1 | -1 | chromosome | SCY1 like pseudokinase 3 [Source:HGNC Symbol;A... | ENSG00000000457.14 | ... | 169809746 | 169810242 | . | 434.0 | . | 10.49881 | -1.0 | 1.78549 | 248.0 | 39389 |
| 1 | ENSG00000000460 | C1orf112 | protein_coding | 169662007 | 169854080 | chr1 | 1 | chromosome | chromosome 1 open reading frame 112 [Source:HG... | ENSG00000000460.17 | ... | 169655862 | 169656358 | . | 78.0 | . | 6.05988 | -1.0 | 0.38208 | 248.0 | 5649 |
| 2 | ENSG00000000938 | FGR | protein_coding | 27612064 | 27635185 | chr1 | -1 | chromosome | FGR proto-oncogene, Src family tyrosine kinase... | ENSG00000000938.13 | ... | 27609989 | 27610485 | . | 78.0 | . | 11.17754 | -1.0 | 2.06285 | 248.0 | 1579 |
| 3 | ENSG00000000971 | CFH | protein_coding | 196651754 | 196752476 | chr1 | 1 | chromosome | complement factor H [Source:HGNC Symbol;Acc:HG... | ENSG00000000971.17 | ... | 196635316 | 196635812 | . | 419.0 | . | 23.07669 | -1.0 | 4.96085 | 248.0 | 15942 |
| 4 | ENSG00000001460 | STPG1 | protein_coding | 24356999 | 24416934 | chr1 | -1 | chromosome | sperm tail PG-rich repeat containing 1 [Source... | ENSG00000001460.18 | ... | 24355241 | 24355737 | . | 78.0 | . | 8.59700 | -1.0 | 1.08362 | 248.0 | 1262 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20007 | ENSG00000242389 | RBMY1E | protein_coding | 21903618 | 21918042 | chrY | -1 | chromosome | RNA binding motif protein Y-linked family 1 me... | ENSG00000242389.9 | ... | <NA> | <NA> | <NA> | NaN | <NA> | NaN | NaN | NaN | NaN | <NA> |
| 20008 | ENSG00000242875 | RBMY1B | protein_coding | 21511338 | 21525786 | chrY | 1 | chromosome | RNA binding motif protein Y-linked family 1 me... | ENSG00000242875.7 | ... | <NA> | <NA> | <NA> | NaN | <NA> | NaN | NaN | NaN | NaN | <NA> |
| 20009 | ENSG00000244395 | RBMY1D | protein_coding | 21880076 | 21894526 | chrY | -1 | chromosome | RNA binding motif protein Y-linked family 1 me... | ENSG00000244395.6 | ... | <NA> | <NA> | <NA> | NaN | <NA> | NaN | NaN | NaN | NaN | <NA> |
| 20010 | ENSG00000258992 | TSPY1 | protein_coding | 9466955 | 9469749 | chrY | 1 | chromosome | testis specific protein Y-linked 1 [Source:HGN... | ENSG00000258992.7 | ... | <NA> | <NA> | <NA> | NaN | <NA> | NaN | NaN | NaN | NaN | <NA> |
| 20011 | ENSG00000280969 | RPS4Y2 | protein_coding | 20756108 | 20781032 | chrY | 1 | chromosome | ribosomal protein S4 Y-linked 2 [Source:HGNC S... | ENSG00000280969.2 | ... | <NA> | <NA> | <NA> | NaN | <NA> | NaN | NaN | NaN | NaN | <NA> |
20012 rows × 22 columns